tesseract とはオープンソースの OCR エンジンです.エンジンのみなので画像を読み取る前に事前におぜん立てをする必要があります.ここでは,tesseract の fedora 36 へのインストールから実際に画像データから文字を読み取りテキストファイルにするまでを説明します.
tesseract のインストール
fedora 36 では dnf コマンドでイントール可能です.これで,日本語の横書き用と縦書き用の学習データもインストールされます.
# dnf -y install tesseract
メタデータの期限切れの最終確認: 0:01:04 時間前の 2022年08月02日 11時35分42秒 に実施しました。
依存関係が解決しました。
===================================================================================================================================
パッケージ アーキテクチャー バージョン リポジトリー サイズ
===================================================================================================================================
インストール:
tesseract x86_64 5.0.1-5.fc36 fedora 1.3 M
依存関係のインストール:
giflib x86_64 5.2.1-14.fc36 updates 51 k
leptonica x86_64 1.82.0-6.fc36 fedora 1.1 M
tesseract-langpack-eng noarch 4.1.0-3.fc36 fedora 1.7 M
tesseract-tessdata-doc noarch 4.1.0-3.fc36 fedora 13 k
弱い依存関係のインストール:
tesseract-langpack-jpn noarch 4.1.0-3.fc36 fedora 1.4 M
tesseract-langpack-jpn_vert noarch 4.1.0-3.fc36 fedora 1.9 M
トランザクションの概要
===================================================================================================================================
インストール 7 パッケージ
ダウンロードサイズの合計: 7.6 M
インストール後のサイズ: 16 M
パッケージのダウンロード:
(1/7): leptonica-1.82.0-6.fc36.x86_64.rpm 1.3 MB/s | 1.1 MB 00:00
(2/7): tesseract-5.0.1-5.fc36.x86_64.rpm 1.4 MB/s | 1.3 MB 00:00
(3/7): tesseract-langpack-eng-4.1.0-3.fc36.noarch.rpm 1.6 MB/s | 1.7 MB 00:01
(4/7): tesseract-tessdata-doc-4.1.0-3.fc36.noarch.rpm 294 kB/s | 13 kB 00:00
(5/7): giflib-5.2.1-14.fc36.x86_64.rpm 1.6 MB/s | 51 kB 00:00
(6/7): tesseract-langpack-jpn-4.1.0-3.fc36.noarch.rpm 4.4 MB/s | 1.4 MB 00:00
(7/7): tesseract-langpack-jpn_vert-4.1.0-3.fc36.noarch.rpm 3.2 MB/s | 1.9 MB 00:00
---------------------------------------------------------------------------------------------------
合計 2.4 MB/s | 7.6 MB 00:03
トランザクションの確認を実行中
トランザクションの確認に成功しました。
トランザクションのテストを実行中
トランザクションのテストに成功しました。
トランザクションを実行中
準備 : 1/1
インストール中 : tesseract-tessdata-doc-4.1.0-3.fc36.noarch 1/7
インストール中 : giflib-5.2.1-14.fc36.x86_64 2/7
インストール中 : leptonica-1.82.0-6.fc36.x86_64 3/7
インストール中 : tesseract-langpack-eng-4.1.0-3.fc36.noarch 4/7
インストール中 : tesseract-langpack-jpn-4.1.0-3.fc36.noarch 5/7
インストール中 : tesseract-langpack-jpn_vert-4.1.0-3.fc36.noarch 6/7
インストール中 : tesseract-5.0.1-5.fc36.x86_64 7/7
scriptletの実行中: tesseract-5.0.1-5.fc36.x86_64 7/7
検証 : leptonica-1.82.0-6.fc36.x86_64 1/7
検証 : tesseract-5.0.1-5.fc36.x86_64 2/7
検証 : tesseract-langpack-eng-4.1.0-3.fc36.noarch 3/7
検証 : tesseract-langpack-jpn-4.1.0-3.fc36.noarch 4/7
検証 : tesseract-langpack-jpn_vert-4.1.0-3.fc36.noarch 5/7
検証 : tesseract-tessdata-doc-4.1.0-3.fc36.noarch 6/7
検証 : giflib-5.2.1-14.fc36.x86_64 7/7
インストール済み:
giflib-5.2.1-14.fc36.x86_64 leptonica-1.82.0-6.fc36.x86_64
tesseract-5.0.1-5.fc36.x86_64 tesseract-langpack-eng-4.1.0-3.fc36.noarch
tesseract-langpack-jpn-4.1.0-3.fc36.noarch tesseract-langpack-jpn_vert-4.1.0-3.fc36.noarch
tesseract-tessdata-doc-4.1.0-3.fc36.noarch
完了しました!画像データの変換
tesseract は pdf は扱えないので png 形式へ変換する必要があります.なお,pdftoppm は fedora36 に標準でインストールされています.
% pdftoppm -png out.pdf out1 ページ 1png ファイルとして出力されます.ファイル名は out-001.png,out-002.png,…となります.
画像からテキストを読み取る
tesseract には日本語 OCR 用の学習データが用意されています.またこれには横書き用と縦書き用が別に用意されています.確認方法は以下のコマンドを実行します.jpn が横書き用,jpn_vert が縦書き用となっています.
% tesseract --list-langs実際に読み取るには以下のようにコマンドを実行します.
% tesseract out-072.png test -l jpn_vertout-072.png(日本語の縦書きで書かれている画像データが格納されている)のテキストデータを test.txt というファイル名で保存します.
tesseract の学習データについて
tesseract の学習データは,自身で学習することもできますし,すでに学習してあるデータを利用することも可能です.学習データについては,今後追記していきます.

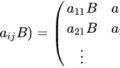
コメント